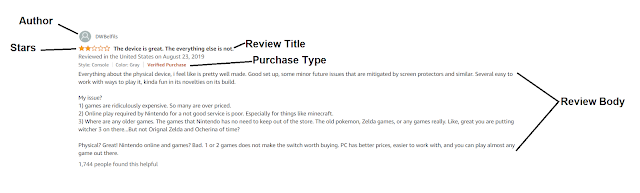
How to trick antibot when scraping for Amazon reviews?

This is a very tricky question actually and a good one as well. Most sites, if not all, protects its resources. When we say resources, that means, information. There are more efficient way of capturing information that is asked from the owner itself. But, asking for it most of the times comes with a dollar value. Though the information posted online is already in a public domain, owners put in place some hurdles for those who would want to capture the data in clever way. Automated web-crawler Anit-bot's job is to challenge, hinder and of course discourage such approach. But those are three were never a deterrent for coders to do the web-scraping approach. Most sites put the information in layers and layers deep into the HTML framework. That's something to tire out the engine from spotting the right data. With programming languages are increasingly smarter and simply get's around it anyway. Web-crawlers are predictable and works in cyclical manner. The key here is "cyc...